Why Konan Voice is
your best choice?
With just text input, you can create high-quality AI voices and 3D characters!
Choose voice actor and character to create your own unique 3D character.
Use Konan Voice to produce a variety of video content.

Konan Voice is a high-quality end-to-end fast speech synthesis solution that utilizes single neural network technology to
automatically synthesize speech waveforms from the entered text in real time.
Video - AI Voice, Konan Voice - 3D Avatar
BENEFITS
Benefit 01.
Presenting a Distinguished Speech Synthesis Solution
The solution converts Korean text to speech files and supports various text forms other than Korean, such as the English alphabet, numbers, and symbols, as well as multiple sampling options and audio encoding in quantum format.

Benefit 02.
Realizing an Innovative Speech Synthesis Service
The solution provides a choice between male and female synthesized speech and also supports synthesis both read and conversational types.
Furthermore, you can enjoy a wide range of options, as the solution provides synthesis between declarative, interrogative, and exclamatory sentences, as well as male and female voice personas with various voice textures and intonations.

Benefit 03.
Vocalization Speed Control
The solution supports synthesized voices slower or faster compared to normal vocalization, and users can also gradually adjust the vocalization speed.

FEATURE
Konan Voice’s high-quality single-speaker speech synthesis engine learns a mass-volume of superior individual speakers’ speech data from vocalization experts, such as “current news anchors” and “voice artists.” The solution also applies the speech duration model and the fast end-to-end speech synthesis technology based on a non-recursive neural network to provide synthesized speech of superb quality comparable to human speech even in real time on the CPU.
In addition, the solution’s multi-speaker and multi-voice color synthesis engine combines high-quality fast end-to-end speech synthesis technology and embedding techniques to synthesize a spectacular persona voice that vividly expresses the unique vocal texture, pronunciation, and style of the individual speaker from only the speaker’s information without re-learning.

High-Quality End-to-End Speech Synthesis
- Applies the state-of-the-art end-to-end speech synthesis technology based on a single network module that independently learns speech synthesizing rules from the training data
- Secures natural sound quality by applying vocal rhythm modeling technology
- Provides high-quality synthetic speech sounds at the level of human vocalization

Speech Synthesis With High Completion
- By applying speech duration modeling technology, it solves the unstable synthesis error issue of conventional end-to-end speech synthesis technologies
- Provides speech synthesis features with high completion level for perfectly commercial service

CPU-Based Fast Speech Synthesis
- Designed the entire neural network module with fast transformer algorithm that has non-recurrent and non-recursive methods
- Provides synthesized speech in real time on the CPU without the need for GPU

Various Vocal Textures and Styles
- Learns from a neural network with large volumes of high-quality vocal data collected from male and female vocal experts, such as current news anchors
- Supports synthesis for read and conversational types
- Supports vocal personas through selection of synthesized voices at the level of hundreds of speakers and vocal textures
Video - Tutorial of Konan Voice 3D Character
TECHNOLOGY

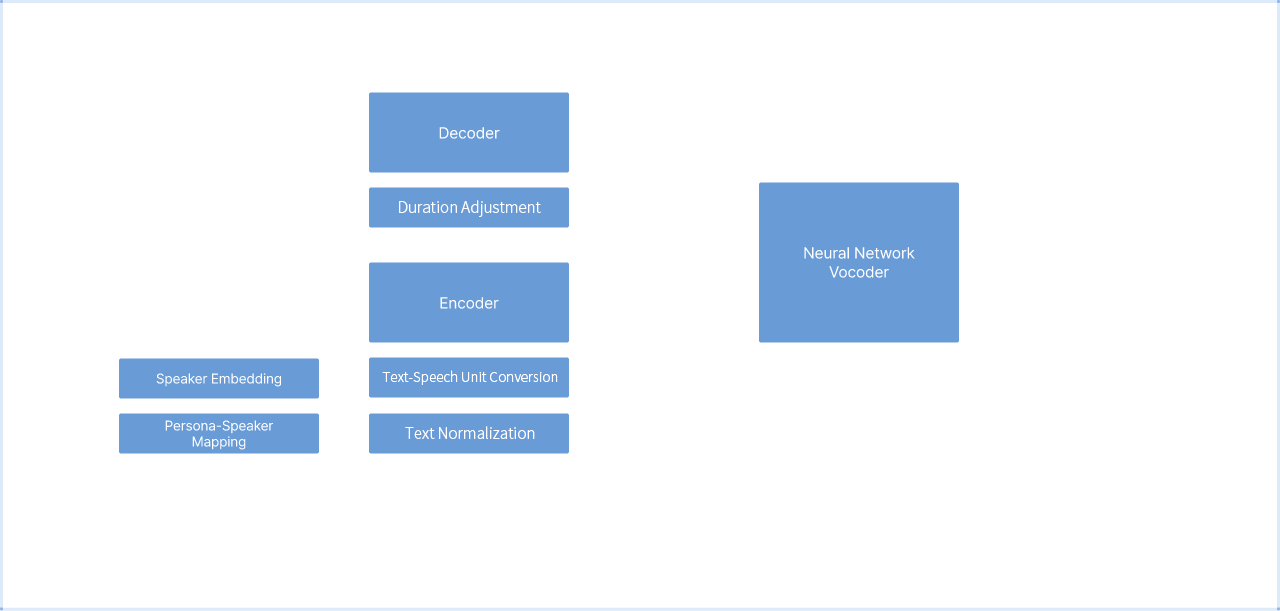
Concept Map - Konan Voice